
![]()
BeeGFS is a parallel cluster file system developed and optimised for HPC. A parallel file system fragments files into several pieces and distributes these across the available storage space, with the aim of allowing simultaneous access and increasing performance in comparison with a classic file system.
BeeGFS is free to use and is used in a large number of TOP 500 supercomputers. BeeGFS works on any Linux machine and consists of different services—storage servers, metadata servers and the client.…
Professional support for the application is offered by ThinkParQ.
BeeGFS major strengths are:
- Scalability – Existing storage can easily be scaled up.
- Flexibility – Works on a large number of machines.
- User friendliness – Clear functionality including graphic interface for administrators.

Scality is a French company that offers a high performance storage software that is scalable, multi-user friendly and affordable.
The solution is used to consolidate unstructured data in a shared storage with the purpose of creating backups (the solution is certified for all backup solutions including VEEAM) and long term archiving (file sync and share (file sharing), big data, AI and analytics, video surveillance)…
IT teams can easily provide services to several departments at once with the agility of public cloud solutions, but from your own data centres all while able to manage your data (lifecycle, search, cost optimisation) in large public clouds when necessary (Azure, Google, AWS, etc.)
The benefits of this solution:
- Hardware agnostic
- Native multi-protocol file and object, S3 & BLOB
- 100% data availability across multiple data centres thanks to advanced geographical distribution that is both hyper agile and efficient.
- Exceptional durability (14 x 9)
- Freedom from a traditional backup model with embedded security measures that enable continuation of business despite DC loss.
- Optimised ROI & TCO compared to traditional NAS approaches
- Multi-cloud functions for synergies with third-party cloud providers
Bright Cluster Manager, developed by Bright Computing, enables the provision and management of HPC clusters. This tool offers a single interface for hardware, operating system, HPC software and users.
Administrators can install clusters fast and keep them running smoothly throughout their entire lifecycle.
The main advantages of Bright Cluster Manager are:
- Easy deployment – Simple and powerful graphical installation tool. Direct installation on barebone servers.
- Easy surveillance – Graphical interface that offers detailed and customisable metrics and warnings when needed. Automatic tests monitor the cluster for you.
- Easy to manage – Choose between GUI or command lines. Optimise the use of your IT resources, HPC tools and libraries.
![]()
OpenHPC is an open source tool set for HPC clusters. These tools enable cluster-based installation, management, resource management, software development, libraries and metric monitoring. OpenHPC’s modular architecture permits users to choose from available components.
Some examples for software that is available on OpenHPC repositories are XCAT, BeeGFS, MPICH, PBS PRO, …
OpenHPC is installed on a master server that the operating system is already installed on.

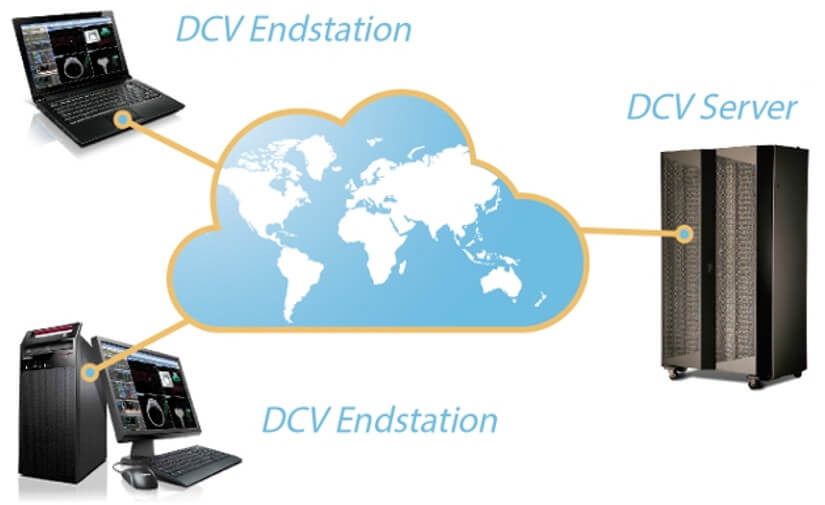
NICE DCV is a technology developed by NICE SOFTWARE that enables users remote access to 2D/3D applications and desktops.
The DCV protocol is capable of adapting to heterogeneous networks (LAN, WAN, VPN) for optimising the user experience, in terms of latency and bandwidth.
The principle behind this technology is simple. A 2D/3D application that is located on a server with one or many graphics cards transmits data that is converted into images by graphic cards. The images are then compressed and sent to clients via the network. These clients only require a simple application or even an internet browser to receive this graphical data and display it. The rendering and user experience are very similar to local use.
NICE DCV is capable of connecting to Windows or Linux desktops for OpenGL and DirectX applications. It’s also possible to split up a GPU into several partitions and allocate each one to a different user (this requires NVIDIA cards).

SLURM is an open source solution for managing a HPC cluster’s resources. This fault-tolerant solution supports clusters of different sizes, from 2 to several thousand nodes.
The three key functions are:
- Allocation of resources or nodes to users for a certain period of time.
- Provision of a framework for starting, executing and monitoring parallel jobs.
- Management of resource conflicts via a queue.

PBS Professional optimises task management and the workload in an HPC environment.
The main functions of PBS Professional are:
- Scalability – Supports millions of cores with minimal latency.
- Strategic planning – Optimal repartitioning of tasks and balancing of response time.
- Resilience – Automatic failover architecture, work never gets lost.
- Flexible plug in framework – Simplifies management by means of better transparency and expandability.
- Monitoring – Framework for error tolerance and monitoring of component status.
Nagios has made a name for itself as the best server monitoring software on the market. What makes it unique is the fact that you do not need a client agent. More than 5000 plug-ins are available that customise the environment to your own needs.
Nagios is available in two editions:
- Nagios Core, which is free but has limited functionality.
- Nagios XI, which is pay-to-use but offers a configuration interface, better monitoring graphics and many other exclusive functions.
Nagios main features are:
- An architecture that is based on flexibility and scalability.
- A framework that focussed on control planning, executing tests, processing, event management and warnings.
- A web interface for displaying the elements that are being monitored by Nagios.
- A wide array of plug-ins that offer additional functions – Configuration interfaces, performance graphs, automatic detection…

Ganglia is a scalable distributed monitoring system for high performance computing systems such as clusters and grids that can show metrics in real time (CPU, RAM, network).…
It is directly available from the packets of the most-used Linux distributions.
Ganglia works on very large clusters but only requires a minimum of space. The tool can be installed on a variety of architectures and is used on more than 500 clusters around the globe. It also enables clusters to be connected over long distances.
The Ganglia ecosystem includes two services for sending and collecting data, a PHP web interface and several useful programs.
Bechtle and Scale Computing have joined forces to provide you with a new solution for hyper-converged infrastructure.
SC//Platform combines virtualisation, server management, storage and backup/disaster recovery into one fully integrated appliance. The highly automated Scale Computing infrastructure has been designed in such a way that downtimes are avoided and it is easy to manage in any IT environment.
Scale Computing is perfect for companies that set great store in the high availability of their applications, simplicity and cost control, as it cuts management costs by 60 to 80% on average.